In this post you will learn about how to restore a PostgreSQL database in Point in time.
Open source databases are taking over other conventional Database softwares at very high speed. For me personally, I really like the way PostgreSQL is designed and it’s simple architecture.
I have tried to write it down every possible steps which will help you to restore your Postgres database.
Below Steps will be same, but few commands may vary with any other backup tool. PITR PostgreSQL
- Allow you to restore database to a specific moment in time PITR.
- It make use of live database files and WAL files.
- This method can only backup and restore the whole cluster, for individual database use pg_dump.
- It can be done when the DB is online.
Step 1. If archive logs not enable then enable it, otherwise go to Step3.
Create Directory for archive logs
mkdir /postgres/postgres12.2/wal_archives
Make changes in postgresql.conf
Postgresql.conf is present under your data directory, in my case it is in /postgres/postgres12.2/data/
wal_level = replica
archive_mode = on # (change requires restart)
archive_command = ‘test ! -f /postgresql/postgres12.2/wal_archives%f && cp %p /postgresql/postgres12.2/wal_archives/%f’
Step2. Restart the cluster
Pg_ctl status -D /Clusterpath
Pg_ctl status -D /postgres/postgres12.2/data/
Pg_ctl –help for more such options

Step3. Insert some data into database
Create table and insert data into it
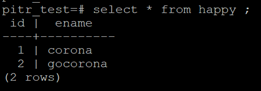
create table happy ( id integer, Ename varchar(20)) ;
INSERT INTO happy ( id,Ename) values (‘01’,’corona’) ;
INSERT INTO happy ( id,Ename) values (‘02’,’gocorona’) ;
Step4. Archive the logs
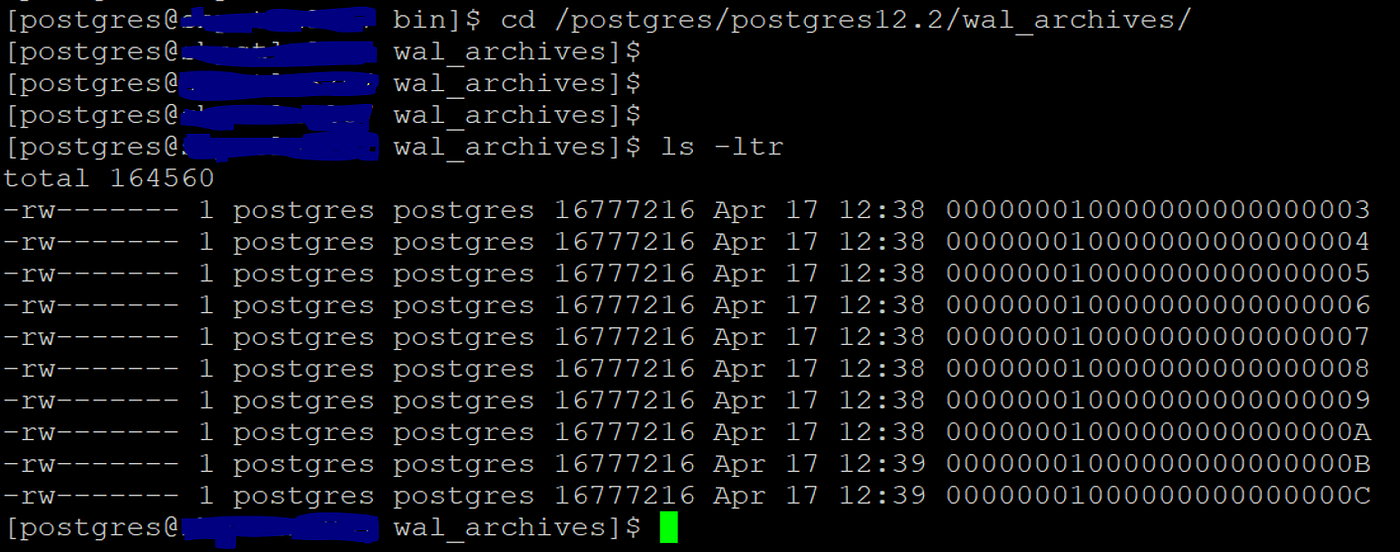
select pg_switch_wal();
and check if files are moving to the archive location.
Step 5. Take the base backup
I am taking the base backup at /postgres/postgres12.2/backup/basebackup
#pg_basebackup -Ft -D /postgres/postgres12.2/backup/basebackup
When we take the base backup, it takes backup of cluster and wal files. Pg_basebackup –help for more such options or https://www.postgresql.org/docs/12/app-pgbasebackup.html

Step6- Stop DB and Delete the cluster.
#pg_ctl stop -D /postgres/postgres12.2/data/

# delete the data files.

Step 7 Restore the Database server
Make sure directories are there before importing. Restore Data folder and WAL folder.
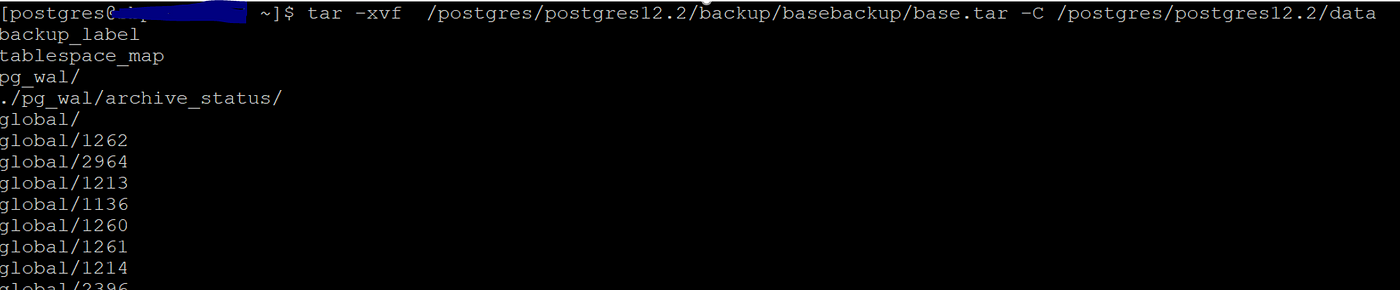
# tar -xvf /postgres/postgres12.2/backup/basebackup/base.tar -C /postgres/postgres12.2/data
# tar -xvf /postgres/postgres12.2/backup/basebackup/pg_wal.tar -C /postgres/postgres12.2/wal/pg12

Now we need to tell our database server to copy files from our archived location to WAL file location. For this we need to edit postgresql.conf file
ADD this
restore_command = ‘cp /postgres/postgres12.2/wal_archives/%f %p’
Step8 — Start the server
./pg_ctl start -D /postgres/postgres12.2/data
Server restored successfully, we can see the table and their data as well. Above step helped us to do a normal restore, for Point in Time recovery, we need to add recovery_target_time parameter in postgresql.conf
Step9- PITR steps
- Take the base backup
./pg_basebackup -Ft -D /postgres/postgres12.2/backup/basebackup
- At this moment there are only 2 rows in HAPPY table, Insert more rows
INSERT INTO happy ( id,Ename) values (‘03’,’GO_corona_GO’) ;
INSERT INTO happy ( id,Ename) values (‘04’,’NO_CORONA’) ;
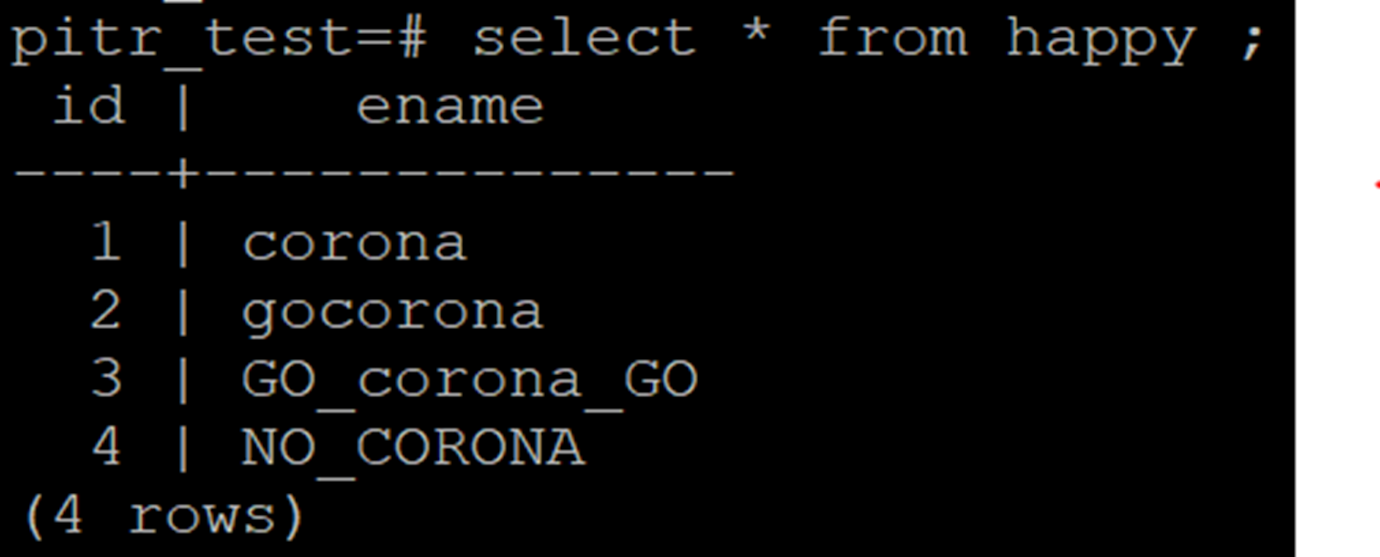
Now we will restore the database before these 2 new rows were inserted using the latest backup and wal files.
- Delete the data directory.
- Restore the DATA directory from Backup
Only /data directory need to be Imported and recovery file will guide the Point in time to backup. As we have done above.
[postgres@ ~]tar -xvf /postgres/postgres12.2/backup/basebackup/base.tar -C /postgres/postgres12.2/data
- Create recovery.signal file and Add parameters
# vi /postgres/postgres12.2/data/recovery.signal
restore_command = ‘cp /postgres/postgres12.2/wal_archives/%f %p’
recovery_target_time = ‘2020–04–17 14:12:00’
Add these 2 parameters in /postgres/postgres12.2/data/postgresql.conf as well.
This is the main part, if we don’t add this parameter then wal files will be applied to the database and we will again have 4 rows.
These two commands should be there in postgresql.conf file as well as recovery.signal file, then start the server.
# ./pg_ctl start -D /postgres/postgres12.2/data/

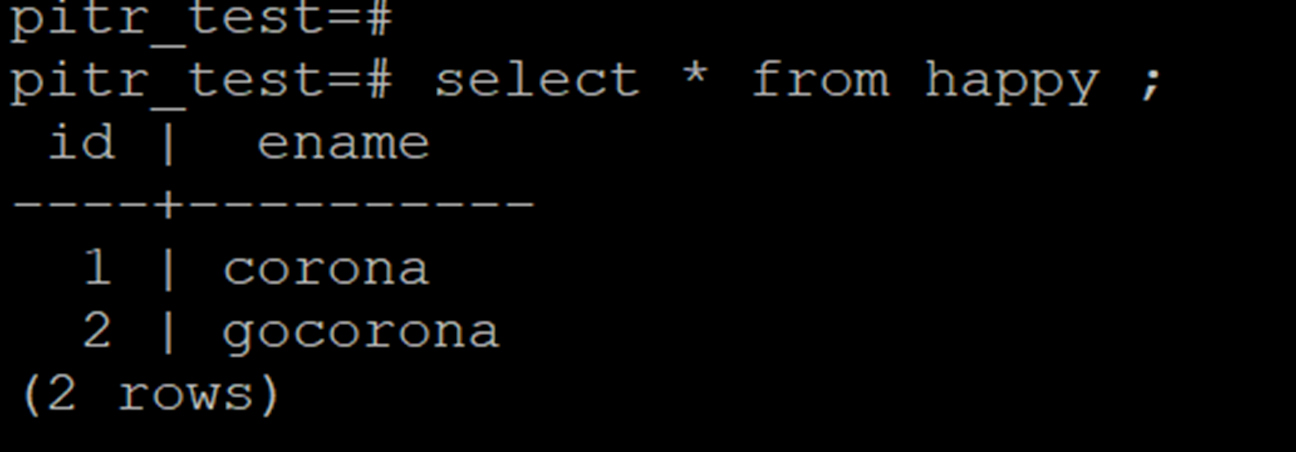
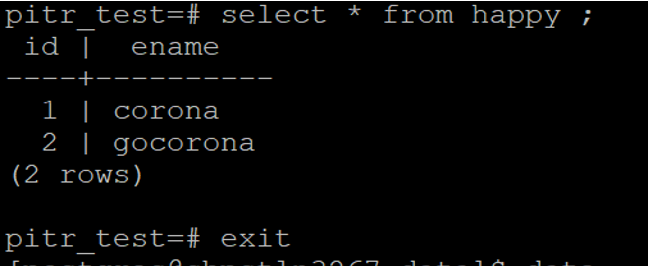
WE HAVE SUCCESSFULLY RESTORED THE DATABASE WITH DESIRED POINT IN TIME.
AS YOU CAN SEE OUTPUT WITH 2 OLD ROWS ONLY.
Comments
Post a Comment