Just yesterday I was reading a tutorial of sorts about how to design a cloud service like Dropbox. Among the many components required to build a large scale service like that, was a metadata database. It would be used to store information about users, their workspaces, files they want to upload, etc. Since it’s mostly just text information and a downstream service needed it to provide a consistent view of the files a user is trying to sync, a relational database would be the perfect choice owing to it’s ACID properties. Now I had heard about ACID properties for as long as I can remember but I wanted to refresh those concepts. So I took a detour from system design to database design.
The Isolation aspect of it really got to me and I wanted to know more about it and more so in the context of postgres. This is an attempt to explain some of what I learned in the process.
Isolation Levels
Isolation is the ability of the transactions to operate concurrently without causing any kind of a side effect. In this article, we’ll go over the different side effects that occur with concurrency and how the different isolation level tries to avoid them.
There are four levels of transaction isolation defined by the SQL standard but postgres only implements three of them. The first level, Read uncommitted, is not present.
The default isolation level in postgres is read committed . To confirm, run this command in psql:
dhruvarora=# SHOW TRANSACTION ISOLATION LEVEL;
transaction_isolation
-----------------------
read committed
(1 row)As we go from read committed to serializable the ‘isolation’ increases and with it the guarantee that concurrently running transactions will not leave the database in a bad state. Let’s see what I mean by a bad state.
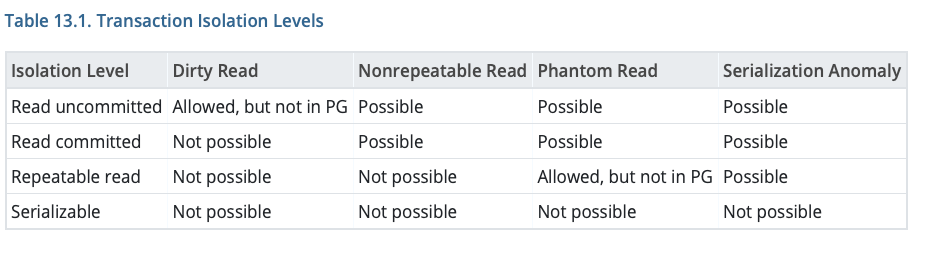
Dirty Read: A transaction reads data which is being updated by an uncommitted concurrent transaction. If the uncommitted transaction succeeds, the data read will not be dirty. But if the transaction rolls back, then the read transaction would have read data which does not exist. Postgres avoid this by showing each transaction a snapshot of data as it was some time ago.

We have an uncommitted transaction on the left trying to update a piece of data. The read transaction on the right is being returned data from before the uncommitted transaction started, hence avoiding a dirty read.
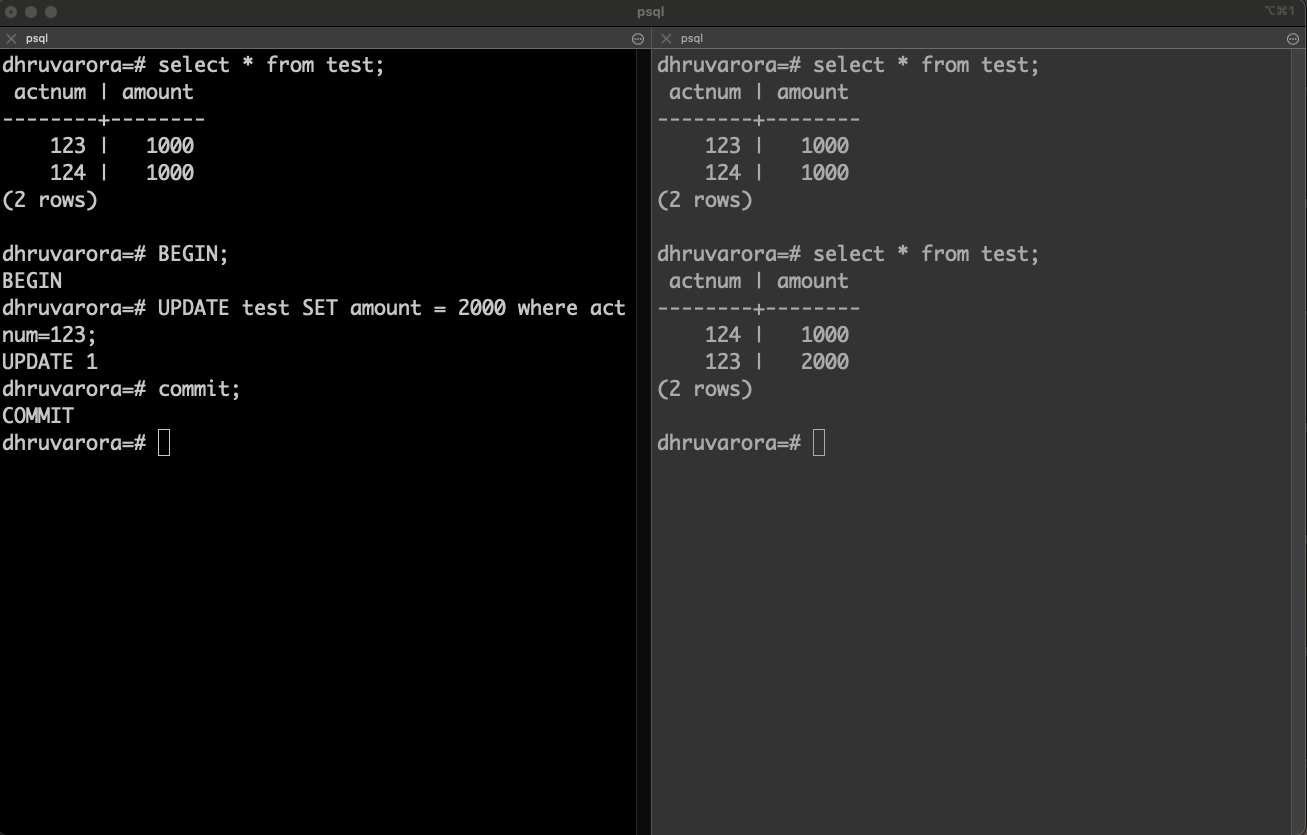
Committing the update transaction returns the new result when issued a second read request.
Nonrepeatable read: A transaction re-reads some data and finds that it was changed by some other transaction that committed since the initial read. With the read committed (default) isolation level in postgres this phenomenon is possible.
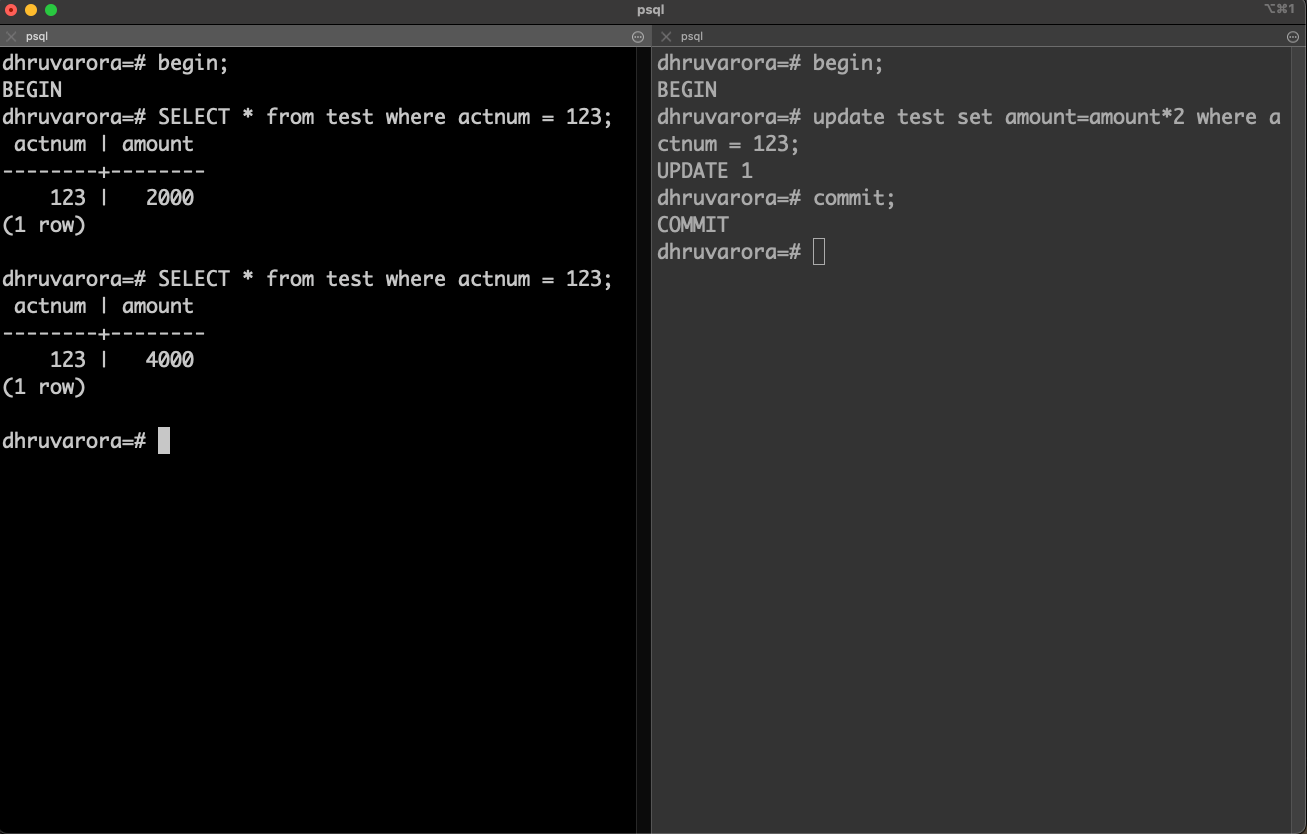
T1: The transaction on the left begins and reads some data. It is not committed.
T2: The transaction on the right begins, updates some data and commits.
T3: The transaction on the left reads the same piece of data it read before but that data was changed at time T2 by another transaction. So the data returned is different this time resulting in a non-repeatable read.
This can be remediated by setting the isolation level to repeatable read. Let’s try doing that.
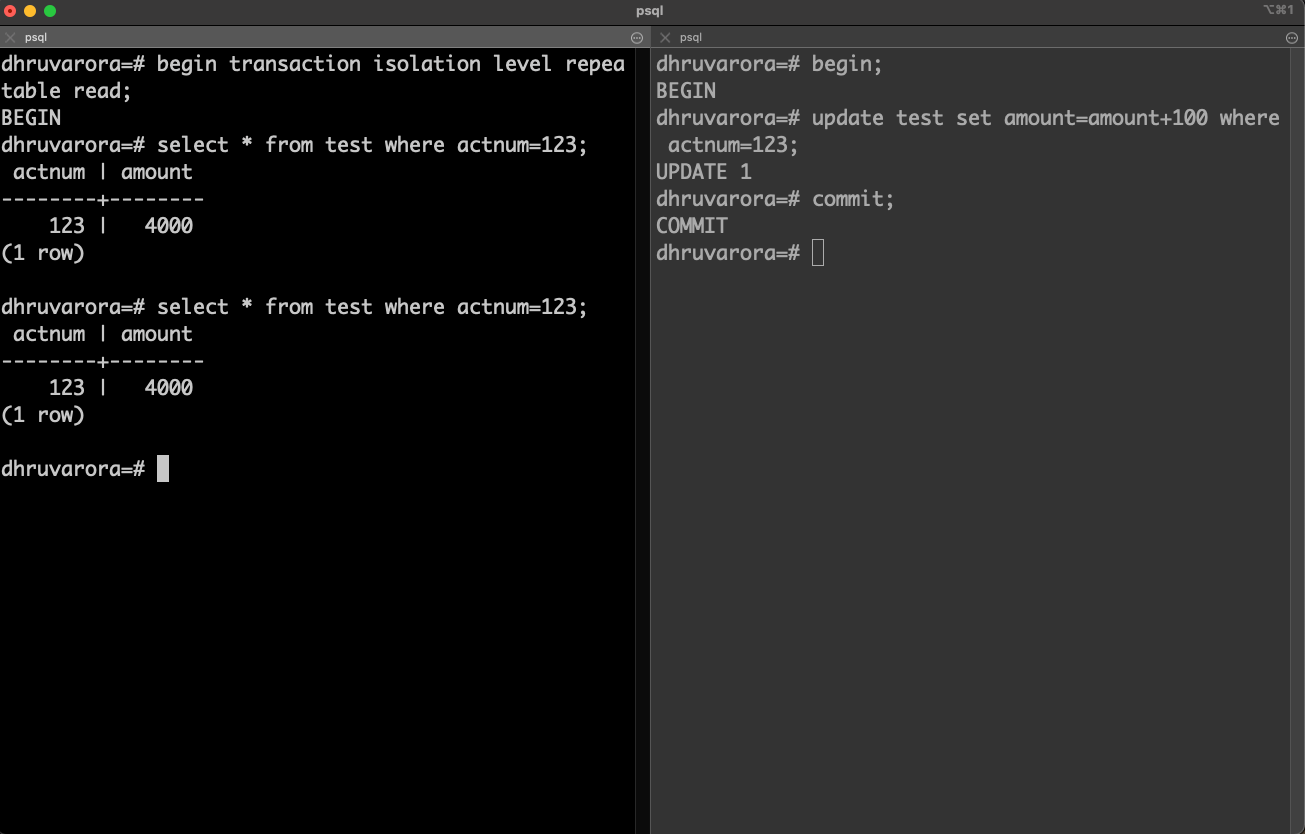
We set the isolation level of the transaction on the left to be repeatable read and the data is the same on both reads in spite of the committed transaction on the right.
Phantom reads: When a transaction re-executes a read query which satisfies a certain search criteria and gets a result set which is different from when the first time the query was executed. The result was changed by a recently committed transaction.

The transaction on the right inserts a new row that matches the criteria for the transaction on the left. When the same query is re-run within the same transaction(left) it fetches a row which was not initially seen.
This can be remediated by setting the isolation level to repeatable read. Let’s try doing that.
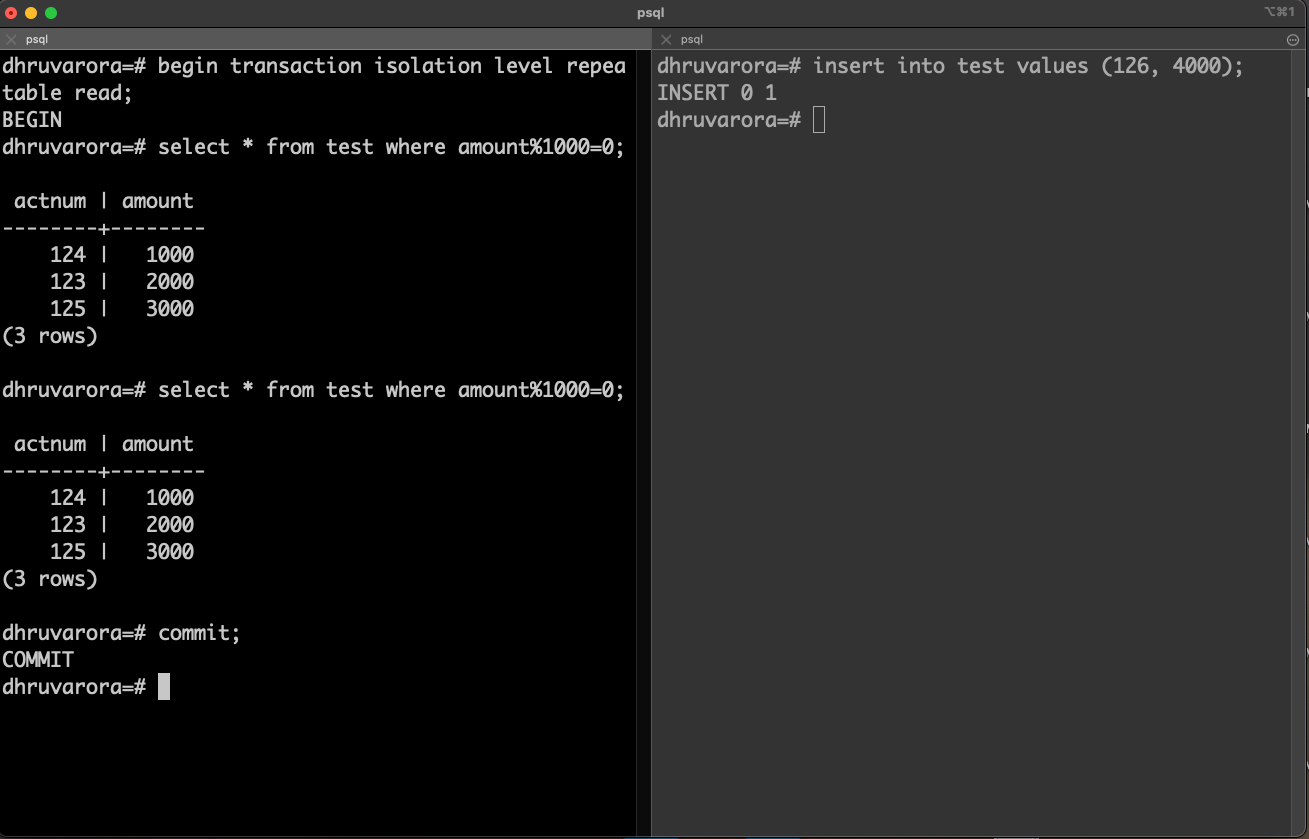
Even though the transaction on the right inserted a new row, the second read for the transaction on the left did not result in a phantom row. The rows returned were same , three, for both read operations.
So how is repeatable read able to avoid Nonrepeatable and phantom reads ? Because the Repeatable Read isolation level only sees data committed before the transaction began; it never sees either uncommitted data or changes committed during transaction execution by concurrent transactions.This level is different from Read Committed in that a query in a repeatable read transaction sees a snapshot as of the start of the first non-transaction-control statement in the transaction, not as of the start of the current statement within the transaction. Thus, successive SELECT commands within a single transaction see the same data, i.e., they do not see changes made by other transactions that committed after their own transaction started. The Repeatable Read isolation level is implemented using a technique known in academic database literature and in some other database products as Snapshot Isolation.
Serialization Anomaly: When the result of successfully committing a group of concurrent transactions is different from all possible combinations of running those transactions one after the other. There are many different types of problems that can occur with concurrent transactions.
Let’s look at a serialization anomaly called write skew and how the serialization isolation level in postgres prevents that. The serialization isolation will detect such anomalies and roll back one or more of the transactions. This level is implemented in postgres using something called Serializable Snapshot Isolation (SSI).
When two concurrent transactions each determine what they are writing based on reading a data set which overlaps what the other is writing, you can get a state which could not occur if either had run before the other. This is known as write skew, and is the simplest form of serialization anomaly against which SSI protects you.
Let’s say we have a table that has the following data:
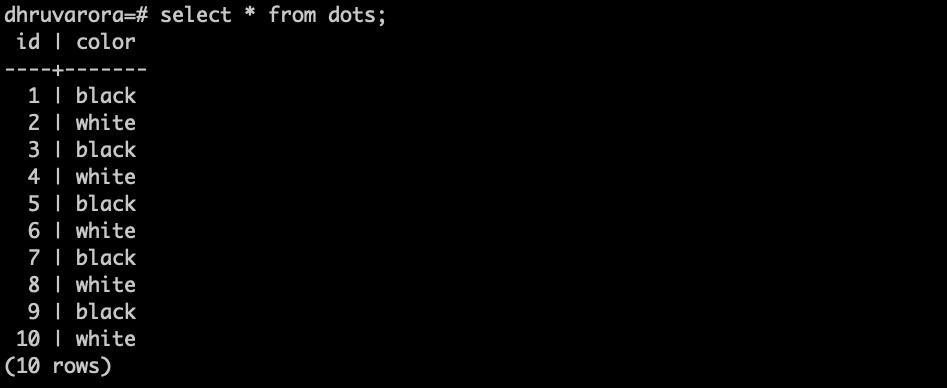
and two concurrent transactions T1 and T2.
T1: Set color = white where color = black
T2: Set color = black where color = white
If these updates are run serially, all colors will match. If T1 runs first followed by T2 all colors will be first set to white by and then finally set to black by T2. They will be all set to white if T2 goes first.
If they are run concurrently in REPEATABLE READ mode, the values will be switched, which is not consistent with any serial order of runs. The black rows will become white rows and vice-versa.
If they are run concurrently in SERIALIZABLE mode, SSI will notice the write skew and roll back one of the transactions. The application can then re-run the rolled back transaction manually. What this essentially means is that this level makes the concurrent transactions logically serializable. The result looks like the transactions have run in some serial order. It is important to understand that the transactions are allowed to physically overlap in the database (a concurrent transaction can start executing before a competing transactions has ended) but the implementation of the serializable isolation level makes sure that they are logically serializable.
The physical execution is free to overlap so long as the database engine ensures the results reflect what would have happened had they executed in one of the possible serial sequences.
To further understand the difference between physical and logical serializability, I highly recommend giving this a read. The SSI wiki also has a lot of great examples to demonstrate serialization anomalies and what the SSI implementation does to avoid them.
Comments
Post a Comment